MapReduce with Durable Azure Functions
Last week I had a talk at the microXchg conference in Berlin about the Azure Functions Durable Extensions. I prepared a sample to show some of the great features of Durable Functions “in action”. After a pretty good feedback I decided to share the sample in this blog post.
Introduction
MapReduce is a pretty common and well known pattern meanwhile. For this sample I decided to process weather data from the US. The map reduce algorithm calculates the maximum temperature of all temperature values provided. This weather data is collected by the National Climatic Data Center (NCDC) from weather sensors all over the world. The data can be found here: ftp://ftp.ncdc.noaa.gov/pub/data/noaa/
All files are zipped by year and the weather station. For this sample I downloaded and unzipped some of them.
Solution Architecture
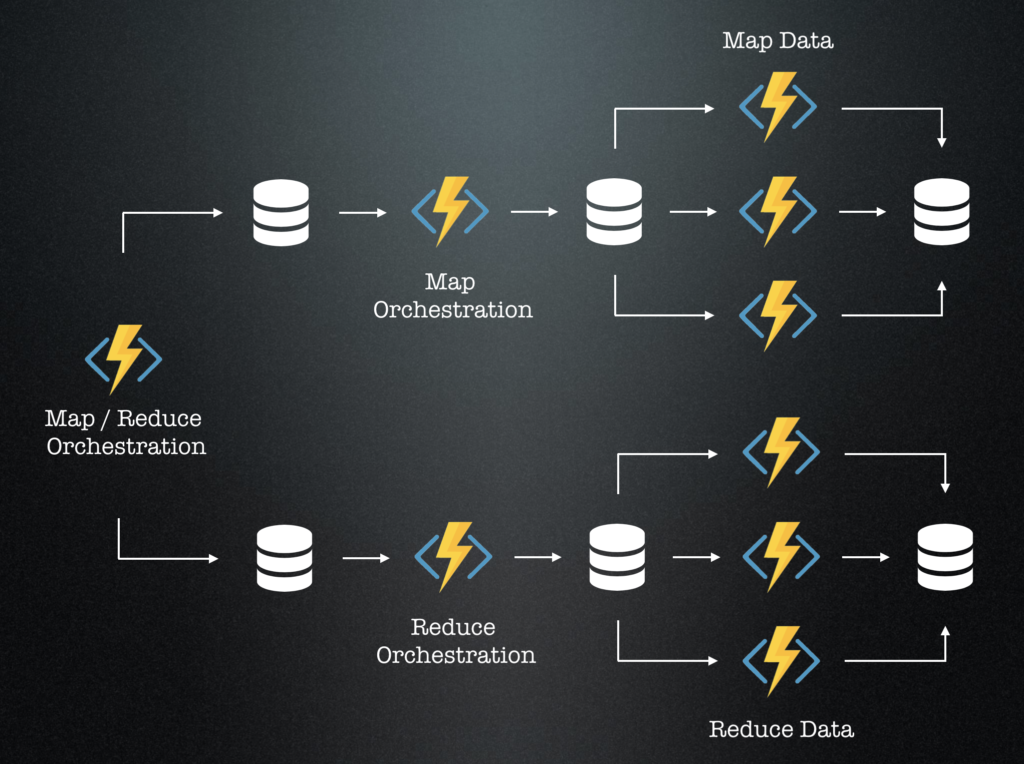
The solution design is to have a “master” orchestration function that handles the overall map-reduce process and two “sub”-orchestration functions where one handles the map and the other one the reduce processing. And finally the “worker” functions which perform the real workload. All in a state-full and recoverable way. The weather data is placed in Azure Storage which enables easy integration with bindings.
Tradeoffs / Limitations
The solution design has some trade-offs due to current limitations/problems in the Durable Function Extension. So I limited the scale of the fan out currently to the number of files processed. Means we call the worker functions “per file”. With some improvements to the Durable Functions Extension there might be a an even more flexible scaling solution design possible in the future.
Starter Function
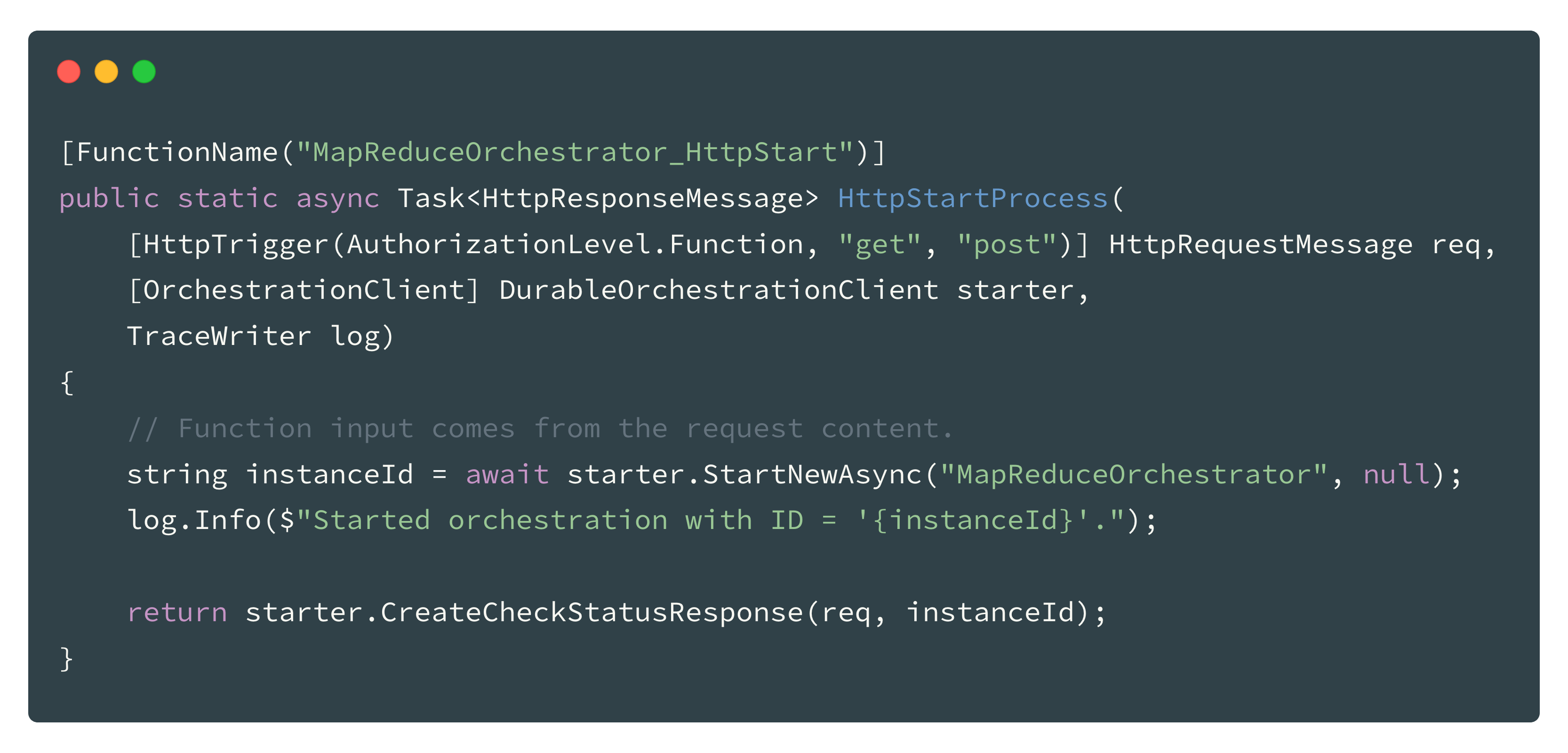
Not mentioned on the solution diagram above is the starter function. This function enables us to start the “root” orchestration which than handles the whole process.
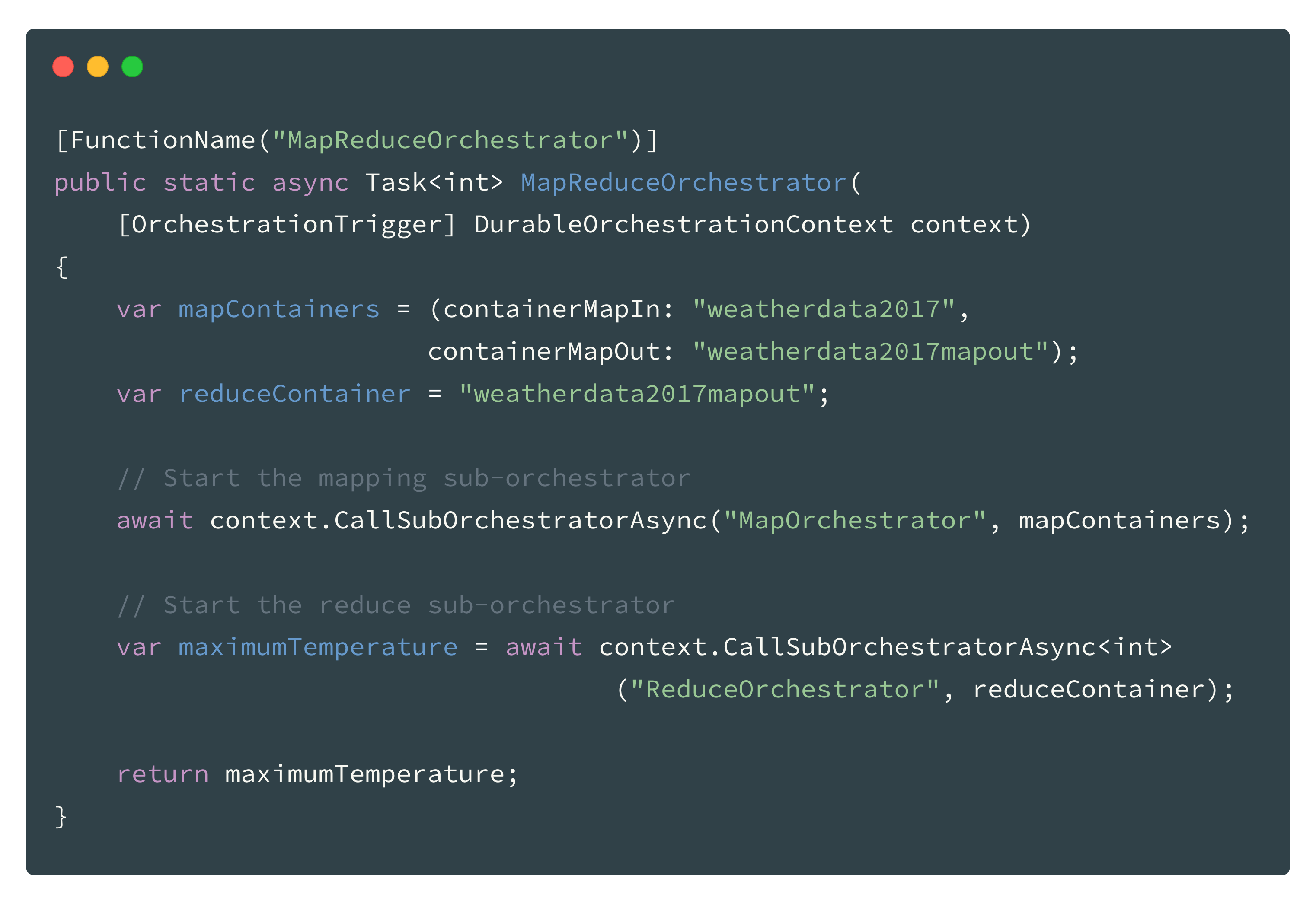
MapReduce Orchestration Function
The map-reduce “root” orchestration function is the coordinator for the whole process and starts the sub-orchestration functions for mapping and reducing.
Map Orchestration Function
The mapping orchestration function receives as parameter the names of the containers where the input resides and the output data of the mapping should be written to. The functions first loads a list of all files that should be processed from the storage and than “fan-out” the data mapping in a loop. Final action is the “fan-in” when awaiting all tasks from the “fan-out” loop.

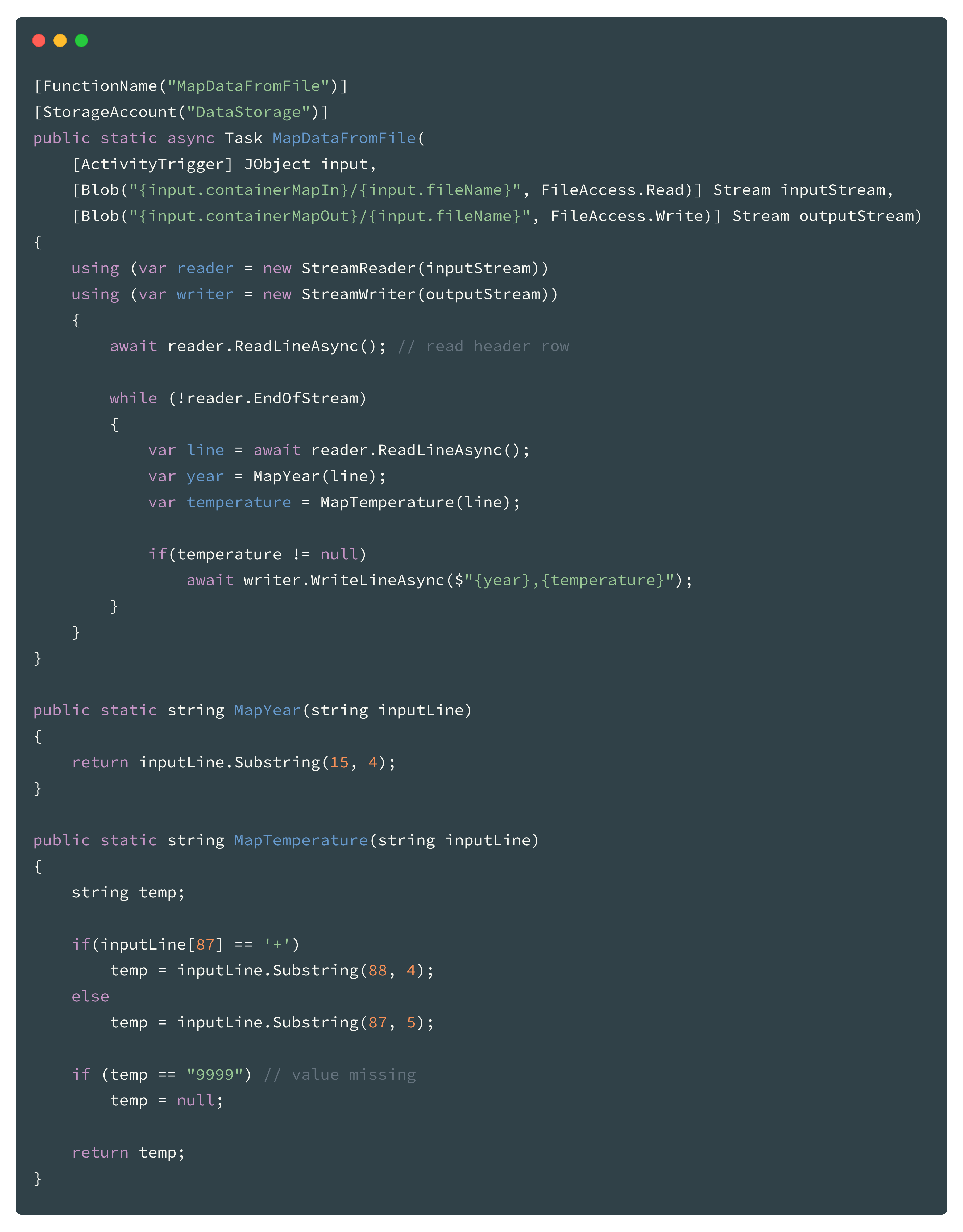
Mapping Function
The mapping function is the worker here. It is called multiple times in parallel from the previous “Map Orchestration Function”. In order to keep the function code as “pure” as possible, we use bindings for the input as well as for the output. So the Azure Function runtime binds the Azure Storage Blobs as a stream here. The functions than “simply” consumes the streams to read and to write data.
The results of the mapping is not transported inline (function return value) here in order avoid “state handling” by the Durable Functions Extension (would bloat). The mapping of the year and the temperature value are done by two little sub functions. (to keep the code a bit more clean)
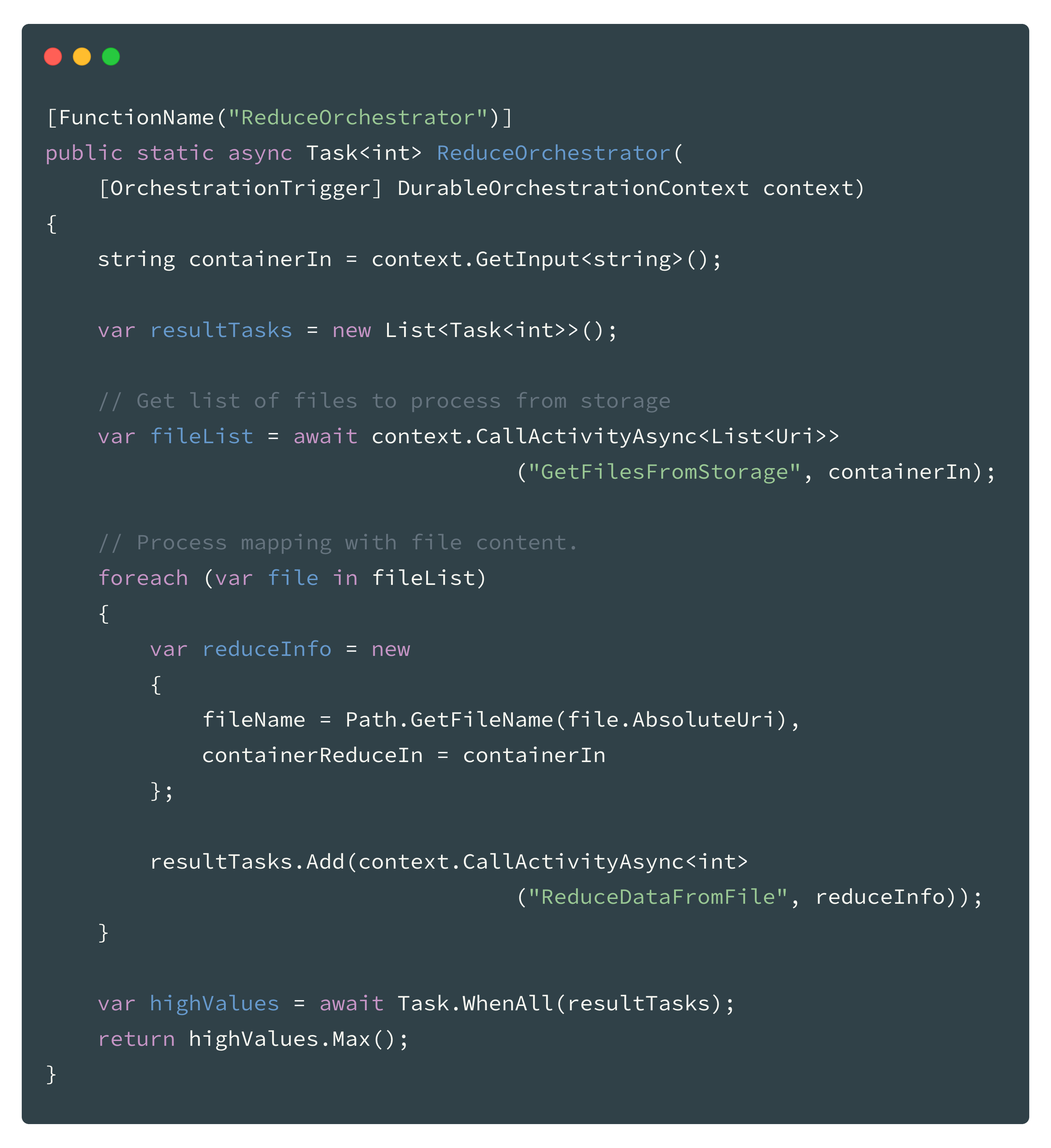
Reduce Orchestration Function
The reduce orchestration function works similar to the mapping orchestration function. It receives the name of the container where the input data (output of mapping) resides in as a parameter. The functions first loads a list of all files that should be processed from the storage and than “fan-out” the reducing in a loop. Finally it awaits all reducer in the “fan-in” and than does a final reduce on all values returned back by the reducers (1 value per file). This is for sure not the best design but good enough for a sample.
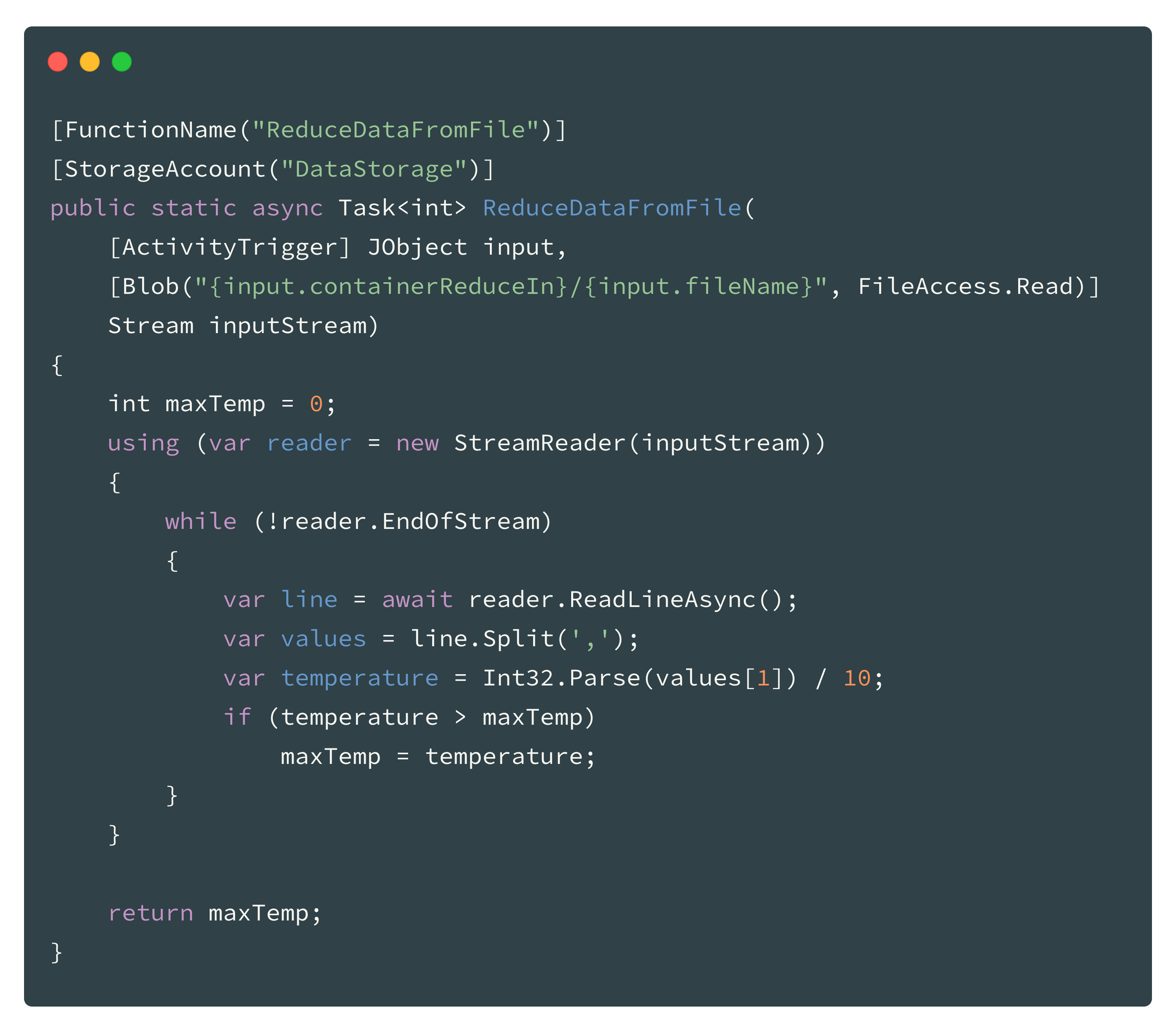
Reducer Function
The reducer function is the second worker here. It is called multiple times in parallel from the previous “Reduce Orchestration Function”. The function consumes the (from the runtime bound) input stream to read the data.
The reducing of the values to a maximum is performed directly inline. The function returns the highest found value in the input file.
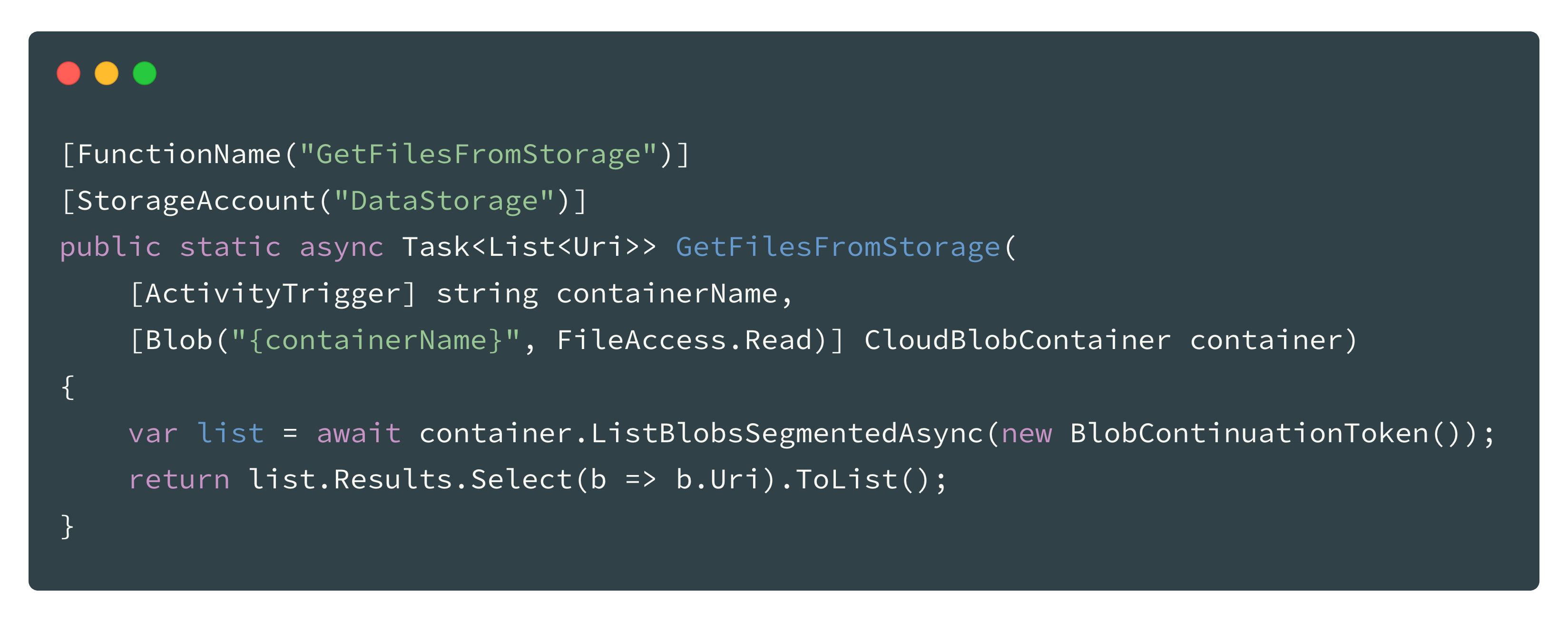
Helper Function
There is a little helper function which enables the orchestration functions to load the list of files from the Azure Storage. This is because orchestration functions should not perform IO operations and the code is a lot cleaner.
(Attention: for simplicity reasons the function does not loop all segments from the storage. In case you want to process more than a couple of files in your test, you have to perform a loop and query the ListBlobsSegmentedAsync function multiple times until you have fetched all files from the container)
Download & Run
The whole sample can be downloaded here. In order to get the sample running just download some of the weather data from the above mentioned ftp server, unzip and upload them to an Azure Storage container of your choice. Don’t forget to configure this storage in the settings of the functions under “DataStorage”.
UPDATE:
You can watch the recording of my session from the microXchg Conference in Berlin here.